Thoughts on R2 and Cloesce Services
Up until now, the focus for Cloesce has been D1 and Workers. We've created Models, which are abstractions over D1 and Workers (a model represents a table, it's method endpoints).
In v0.0.5, we will introduce Services and Cloudflare R2, both of which are not necessarily tied to a model.
Services
The key idea of a Service is that Workers endpoints should not be forced to exist on a Model, because that would force a SQL table to exist. A Cloesce application should even be able to run without the presence of any Models or a D1 database, running entirely from services.
Within Cloesce, a Service is just a singleton namespace for methods, which can optionally capture a closure of dependency injected values.
For example, a basic service declaration in TS would look like:
@Service
export class FooService {
@POST
async foo(...) {} // instantiated method
@GET
static bar(...) {} // static method
foo() {} // doesn't have to be exposed as a Worker endpoint
}
Attributes on a FooService must be dependency injected values, and we will assume that is the case by default.
@Service
export class FooService {
env: Env;
async foo(...) {
this.env.db ...
this.bar ...
}
bar(...) {
// static, can't use env or bar
// note: not sure why anyone would want a static method for a service
}
}
Services should exist as dependencies in our depenency injection container. Thus, Services can reference one another:
@Service
export class FooService {
env: Env;
bar: BarService;
// or equivalently
func(@Inject bar: BarService) {
...
}
}
Just like in Models, cyclical dependencies will have to be detected at compile time. It may be possible to allow cyclical composition through lazy instantiation, but that can be saved for another milestone.
Client Side
There is no reason for the client API to think of Services as instances, since the attributes of a service are not accessible to the client (injected dependencies). Services will default to static calls on the client.
@Service
export class FooService {
env: Env;
bar: BarService;
@POST
foo() {}
}
// => client code
export class FooService {
static async foo(): Promise<HttpResult<void>> {...}
}
Cloesce Router Interface with Services
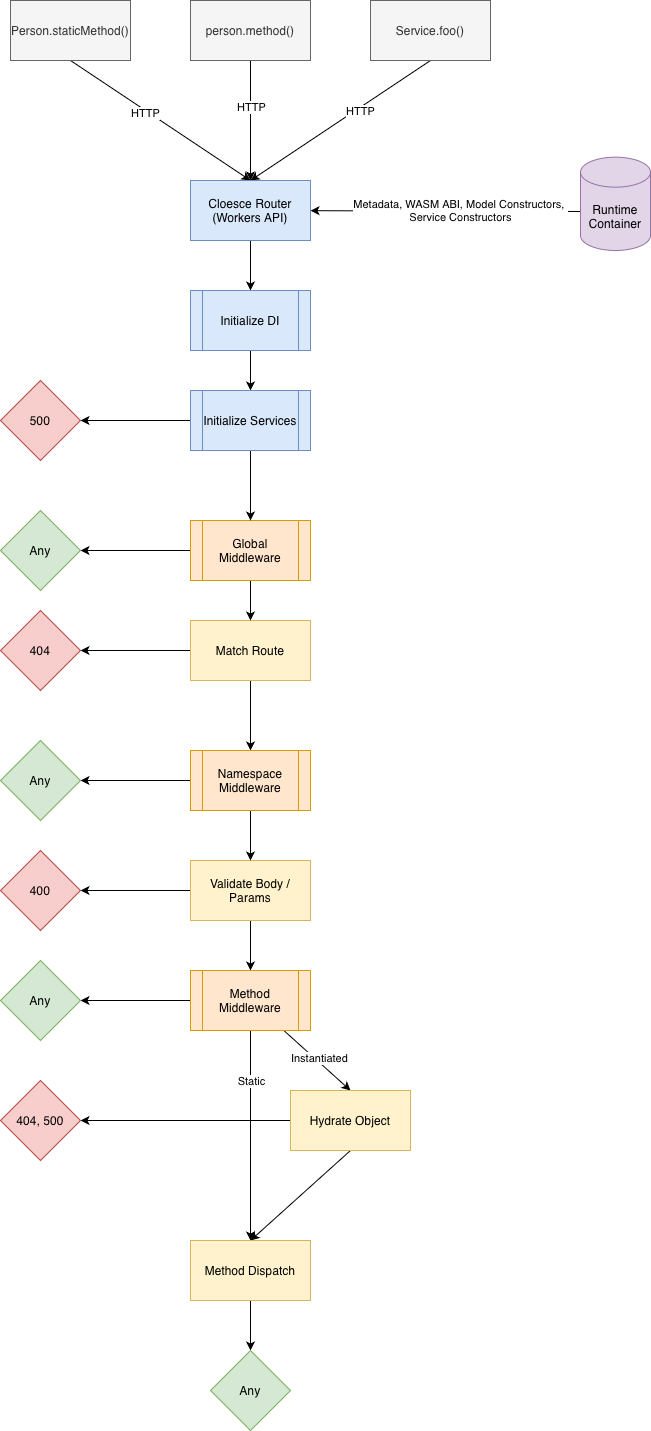
Since Cloesce is to be implemented in several languages, we've been building an interface that all languages will follow. Services have been defined very similarly to Models, and won't be difficult to add into the router interface because of that. A new important step will be initializing and injecting all services, meaning we construct every object in topological order and insert it into the DI container. Middleware should be capable of intercepting Services and their methods as well. Lastly, Hydration will now diverge to return a Service instance instead of always querying D1.
Blobs and R2
R2 is Cloudflares object storage platform. Objects are stored under a namespace called a bucket, with each value having it's own unique key. Keys are decided by the developer, and are not generated by R2. Files, images, and other kinds of data are classified as blobs (binary large objects). Cloesce operates using Workers, and an important limitation of Workers is that the maximum amount of memory of any instance is 128MB. This means large objects cannot be be fully buffered in memory for a worker, and must be streamed to some destination using the Worker as a pipe.
Since R2 is S3 compatible, an alternative is supprted via signed uploads and signed downloads. Essentially, a Worker can query the Cloudflare API to ask "give me cryptographic permission to do this file upload/download", and a link will be returned like:
https://bucket.r2.cloudflarestorage.com/uploads/123.png?X-Amz-Expires=600&X-Amz-Signature=abc123...",
The client is then responsible for uploading their file to the link. A typical pattern servers follow is having some upload endpoint foo/upload, and then having some complete endpoint foo/upload/complete, where they can tell the server "I've successfully done an upload". Note that an upload could fail, in which an orphaned R2 blob would exist, forcing some periodic orphan killer to exist.
For this milestone, trying to create an interface to abstract and orchestrate the signed upload process feels out of scope. However, there is no reason for us to prohibit uploading and downloading blobs.
Blob, Stream, Media Type
To support Blobs, we will add them into the Cloesce grammar. SQLite supports a Blob type as well, meaning it is a valid column type for a Model. The way Blobs move through a REST API is vastly different than pure application/json data, which is all we've been dealing with up until now. JSON is meant for structured data, under a strict text format. JSON text is all buffered into memory by default. On the other hand blob uploads are typically done as application/octet-stream. Combining the two requires inline-serializing Blobs to base64.
Incoming and Outgoing Blob
Imagine a method takes a Blob as an argument.
@POST
fooBlob(blob: Blob) {}
There is no JSON data, just a single blob. We can send this as an octet stream.
// Client
const blob = new Blob([someUint8Array], { type: "application/octet-stream" });
await fetch("/api/upload", {
method: "POST",
headers: {
"Content-Type": "application/octet-stream",
},
body: blob,
});
When an octet stream is recieved on the server, a decision needs to be made. Do I buffer this into memory, or do I treat this as a stream of bytes? To solve this dilemma, we will split the Blob type into two: Stream and Blob.
Blob will be the decision to buffer into memory. This could hit the Workers memory limit. Stream will be the decision to accept a ReadableStream, which Cloudflare directly supports on Workers.
// Server
@POST
fooBlob(blob: Blob) {} // => Buffer into memory
async fooBlob(stream: Stream) {} // => Readable stream
This will also have to be supported in the reverse case. When outgoing blob data is sent from the server, the same logic will have to happen on the client. For example, this service will produce two different types on the client when invoked.
@Service
class BlobService {
@GET
async getBlob(): Blob
@GET
async getStream(): Stream
}
Encoding Blobs in Base64 JSON Strings
It's reasonable to have methods that have both Blobs and JSON, ex:
@POST
fooBlob(blob: Blob, obj: SomeObj, color: string) {}
This comes with a caveat. We cannot use a Stream here, because there are other parameters in the mix. Encoding the blob to b64 will allow representing both the binary data and the metadata. This means the only way to convey this endpoint in REST is to load the buffer in memory, potentially hitting the memory limit. It's also worth noting encoding and decoding a significant binary is cumbersome. A sufficient warning should be displayed in this case.
Determining Endpoint Media Type
We will need to define a MediaType in the CIDL: MediaType::Octet | MediaType::Json. Each method will have to mark its set of parameters under a MediaType, and its return value under a MediaType. We can do this in the generator portion, after intaking the cidl.pre.json, adding a media type to the end. The backend will then assume that the MediaType sent by the frontend is correct (or throw a 415), and the client will assume that the server is sending the correct MediaType. Note that the server could return an error which would be text. if the server responds with the incorrect media type, we will want some fatal error to occur, as the generated code should always be synced (this should only happen if the CIDL was tampered with).
R2
Uploading to R2 won't be supported in this milestone (though a developer can easily make a Stream endpoint with the above section implemented). However, there is no reason we can't help with downloading from R2.
Generally, R2 key information is stored in SQL associated with some metadata. This enters the domain of our Cloesce Models. As talked about in the previous section, Blobs cannot be streamed JSON data. But we can return a signed download URL to access the blob, along with all of the blob metadata. For directly supporting R2, I propose creating a new navigation property for this express purpose, and integrating it into our ORM.
First, the WranglerEnv must support R2 and help with generating configs.. R2Bucket's are the Wrangler API to interact with any R2 bucket. We can generate the toml bindings if buckets are defined. Key information will also be necessary for generating signed download URLs.
@WranglerEnv
class Env {
someBucket: R2Bucket;
anotherBucket: R2Bucket;
endpoint: R2Endpoint;
accessKeyId: R2AccessKeyId;
secretAccessKey: R2SecretAccessKey;
}
producing a wrangler config:
[[r2_buckets]]
binding = "someBucket"
bucket_name = "someBucket"
[[r2_buckets]]
binding = "anotherBucket"
bucket_name = "anotherBucket"
[[vars]]
endpoint = "xxxx"
A .dev.vars will be generated for sensitive info:
accessKeyId="xxxx"
secretAccessKey="xxxx"
Note that we cannot validate that the access key and secret access key exists at compile time. This is because production CF apps use wrangler secret put SOME_KEY, which Cloesce cannot access. This means an error could occur at runtime.
Uploads
If a developer wishes to not use a signed upload URL, they're always welcome to use the Blob type, Stream for large objects or even orchestrate their own signed url process. For example:
@D1
class Comment {
@PrimaryKey
id: Integer;
body: string;
gif: string;
@POST
static async post(@Inject env: Env, comment: Comment, gif: Blob) {
await this.env.someBucket.put("my key", gif);
// ...
await orm.upsert(Comment, {
...comment,
gif: "my key",
});
}
@POST
async postBigGif(@Inject env: env, gif: Stream) {
...
// note this is an instantiated method, posting a gif has to be done after an object is instantiated
// for the stream to be allowed
}
}
List, Get
Signed downloads can be handeled entirely through Cloesce, with a new R2 navigation property
@D1
@CRUD(["GET", "LIST"])
class Comment {
@PrimaryKey
id: Integer;
body: string;
gif: string;
@R2({
bucket: "someBucket",
keyColumn: "gif",
})
gifDownloadUrl: R2Download | undefined;
@DataSource
static readonly withDownload: IncludeTree<Comment> = {
gifDownloadUrl: {
// We should try to place the S3 Type "GetObjectRequest" in here
// though I'm not sure if the TS type system would allow that.
//
// If impossible, we might just want to revamp how IncludeTrees are generated,
// potentially creating a custom builder.
}
}
}
// where R2Download is some class
class R2Download {
url: string;
// metadata from `head object`
size: number;
etag: string;
...
// https://docs.aws.amazon.com/AmazonS3/latest/API/API_HeadObject.html
}
With this navigation property gifDownloadUrl will be populated with metadata on the blob, along with the signed download url. Like the D1 navigation properties, R2 must be included with an IncludeTree, via a data source. The ORM function mapSql will have to populate download URLs if the include tree references them.
Note: Theres a lot of different options available when creating a signed url
const input = {
// GetObjectRequest
Bucket: "STRING_VALUE", // required
IfMatch: "STRING_VALUE",
IfModifiedSince: new Date("TIMESTAMP"),
IfNoneMatch: "STRING_VALUE",
IfUnmodifiedSince: new Date("TIMESTAMP"),
Key: "STRING_VALUE", // required
Range: "STRING_VALUE",
ResponseCacheControl: "STRING_VALUE",
ResponseContentDisposition: "STRING_VALUE",
ResponseContentEncoding: "STRING_VALUE",
ResponseContentLanguage: "STRING_VALUE",
ResponseContentType: "STRING_VALUE",
ResponseExpires: new Date("TIMESTAMP"),
VersionId: "STRING_VALUE",
SSECustomerAlgorithm: "STRING_VALUE",
SSECustomerKey: "STRING_VALUE",
SSECustomerKeyMD5: "STRING_VALUE",
RequestPayer: "requester",
PartNumber: Number("int"),
ExpectedBucketOwner: "STRING_VALUE",
ChecksumMode: "ENABLED",
};
Summary of Changes
- Introduce Cloesce Services
- Add
BlobSQL column type - Add
Blob,StreamCIDL Types - Add
MediaTypeenum for a methods parameters and return value - Switch behavior on the router based off
MediaType - Switch behavior on the client API based off
MediaType - Add R2 Wrangler config generation / support
- Add R2 Navigation Property; Generate signed download URLs