Thoughts on v0.0.2 Foreign Keys
Naive World View
Foreign key relationships can be naively mapped to object composition.
(1:1) Person has a Dog
class Dog {
id: number;
}
class Person {
id: number;
dog: Dog; // | null
}
(1:M, M:1) A person has many dogs, many dogs have one person. In SQL, this relationship is shown backwards: a dog has a foreign key to a Person
class Person {
id: number;
dogs: Dog[];
}
class Dog {
id: number;
}
(M:M) A student has many classes, a class has many students
class Student {
id: number;
classes: Class[];
}
class Class {
id: number;
students: Students[];
}
Problems with naive view
The direct object mapping is naive because of two problems:
- Cartesian explosions
- Recursive definitions
Both of these issues will significantly reduce performance, usability, and most importantly, charge the developer a significant amount of money per query for more complex models who have deep nested composition.
To demonstrate a recursive definition, let's use our M:M example of Students to Classes. Assume I want to return a list of Student models from the database (represent as JSON). If we follow the naive pattern (Student has a list of classes, classes have a list of students...) we might run into a recursive model:
{
"students": [
{
"name": "Student0",
"classes": [
{
"name": "Class0",
"students": [
{
"name": "Student1",
"classes": [
{
"name": "Class0"
...
}
]
}
]
}
]
}
]
}
Cartesian explosions on the other hand happen when many joins are done on a table. Let a student have an enrollment which has classes, and let classes have textbooks:
SELECT
s.Name AS StudentName,
c.Name AS ClassName,
t.Title AS TextbookTitle
FROM Students s
LEFT JOIN Enrollments e ON s.Id = e.StudentId
LEFT JOIN Classes c ON e.ClassId = c.Id
LEFT JOIN ClassTextbooks ct ON c.Id = ct.ClassId
LEFT JOIN Textbooks t ON ct.TextbookId = t.Id
ORDER BY s.Name, c.Name, t.Title;
Assuming a student is enrolled in 5 classes, and each class has 3 textbooks, a single query would return 15 rows consisting of all the joined information. See single vs split queries for the Entity Framework solution.
Data Sources
GraphQL and Entity Framework solve these issues in similiar ways, by having an explicit map (or tree) of what to include. For the M:M example, GraphQL would make you specify the exact result structure of a query:
query {
students {
id
classes {
id
students {
id
}
}
}
}
Entity Framework does something similiar using it's Fluent API pattern. Note it only cares about FK's.
var students = db.Students
.Include(s => s.Classes)
.ThenInclude(c => c.Students)
.ToList();
IntelliTect's Coalesce tackles this issue by introducing a "Data Source". The Coalesce docs mention that the default data source will "load all of the immediate relationships of the object (parent objects and child collections), as well as the far side of many-to-many relationships". Coalesce also allows you to specify your own include trees, which serialize to the frontend such that they can use a specific data source. This takes advantage of Entity Framework's include tree.
Data sources are only relevant on generated endpoints, when querying the database in Coalesce the Include API has to be used.
public class Person
{
[DefaultDataSource]
public class IncludeFamily : StandardDataSource<Person, AppDbContext>
{
public IncludeFamily(CrudContext<AppDbContext> context) : base(context) { }
public override IQueryable<Person> GetQuery(IDataSourceParameters parameters)
=> Db.People
.Where(f => User.IsInRole("Admin") || f.CreatedById == User.GetUserId())
.Include(f => f.Parents).ThenInclude(s => s.Parents)
.Include(f => f.Cousins).ThenInclude(s => s.Parents);
}
}
[Coalesce]
public class NamesStartingWithA : StandardDataSource<Person, AppDbContext>
{
public NamesStartingWithA(CrudContext<AppDbContext> context) : base(context) { }
public override IQueryable<Person> GetQuery(IDataSourceParameters parameters)
=> Db.People.Include(f => f.Siblings).Where(f => f.FirstName.StartsWith("A"));
}
Then, on the frontend, a client API is generated:
var viewModel = new PersonViewModel();
viewModel.$dataSource = new Person.DataSources.IncludeFamily();
viewModel.$load(1);
Coalesce's implicit data source is an area confusion for new developers, when it's first encountered there is generally a "hey why is this list empty" with a deeply nested model, followed by time spent debugging in all the wrong places.
For now, we will have explicit data sources and default to no FK's unless directly given.
It's also worth noting we can't make nice filters like NamesStartingWithA, because Cloesce doesn't have an ORM (we may try to make one in the future). Our design will mostly take inspiration from GraphQL's query builder (but only care about FK's, like Entity Framework).
// Really the only time TypeScript has been nice, I assume this won't be easy
// in other languages
type IncludeTree<T> = {
[K in keyof T]?: T[K] extends ClassType ? IncludeTree<T[K]> : never;
};
class Cat {...}
class Treat {...}
class Dog {
...
treat: Treat | undefined;
}
class Person {
id: number;
dog: Dog | undefined; // | null
cat: Cat | undefined; // | null
// This data source will be used by all endpoints unless it's overriden
@DataSource("default")
readonly default: IncludeTree<Person> = {
dog: { treat: {} },
cat: {},
};
@DataSource("noCats")
readonly noCats: IncludeTree<Person> = {
dog: { treat: {} },
};
@DataSource("nothin")
readonly nothin: IncludeTree<Person> = {};
async animals(): Person {
return {
this.dog,
this.cat
}
}
}
//... frontend
let person: Person = ...
await person.animals() // => {dog: { treat: {} }, cat: {} }
await person.animals(Person.dataSources.noCats) // => {dog: { treat: {} } }
await person.animals(Person.dataSources.nothin) // => {}
I think this is a great compromise. It's less boilerplate than GraphQL, the developer only needs to concern themselves with FK's. It's also less boilerplate than Coalesce (losing some versatility of course). Writing data sources will definitely be annoying, so in the future we will address this with more custom include trees, maybe introducing helpers like IncludeTree<Person>(breadth = N).
Generation
Let's finally talk code generation. In order to make this all work, we will need to introduce some new types: Data Sources, Foreign Keys, and Many to Many relationships.
Side note: Eventually, I'd like to introduce an "AutoMagic" update to Cloesce making decorators completely optional, "magically" inferring by context. For MVP we will keep them explicit.
class Student {
@PrimaryKey
id: number;
@ManyToMany
classes: Class[];
}
class Class {
@PrimaryKey
id: number;
@ManyToMany
students: Students[];
}
class Treat {
@PrimaryKey
id: number;
}
class Dog {
@PrimaryKey
id: number;
@ForeignKey
treat: Treat | undefined;
}
class Person {
@PrimaryKey
id: number;
@ForeignKey
dogId: number;
dog: Dog | undefined;
// By default, we will only include Person's attributes, so this will explicitly say
// "fetch that dogs and his treat too"
@DataSource("default")
readonly default: IncludeTree<Person> = {
dog: { treat: {} },
};
}
roughly making the CIDL
{
"models": [
{
"name": "Person",
"attributes": [
// ...
{
"foreign_key": {
"OneToOne": "Dog"
},
"value": {
"cidl_type": "Integer",
"name": "dogId",
"nullable": false
}
},
{
"foreign_key": {
"OneToOne": "Dog"
},
"value": {
"cidl_type": { "model": "Dog" },
"name": "dogId",
"nullable": false
}
}
],
// explicitly created data source, includes treat
"data_sources": [
{
"name": "default",
"include": [
{
"cidl_type": { "model": "Dog" },
"name": "dog",
"nullable": false,
"include": [
{
"cidl_type": { "model": "Treat" },
"name": "treat",
"nullable": false,
"include": []
}
]
}
]
}
]
},
// Skipping dog, treat...
{
"name": "Student",
"attributes": [
{
"foreign_key": {
"ManyToMany": "Class"
},
"value": {
"cidl_type": { "array": { "model": "Class" } },
"name": "classes",
"nullable": false
}
}
],
// No implicit data sources for now.
"data_sources": []
},
{
"name": "Class",
"attributes": [
{
"foreign_key": {
"ManyToMany": "Student"
},
"value": {
"cidl_type": { "array": { "model": "Student" } },
"name": "students",
"nullable": false
}
}
],
// No implicit data sources for now.
"data_sources": []
}
]
}
The tricky part with generation is the order of table creation. If B depends on A, in Sqlite A must be created first. It'll be important to create a model dependency graph. Using the previous CIDL:
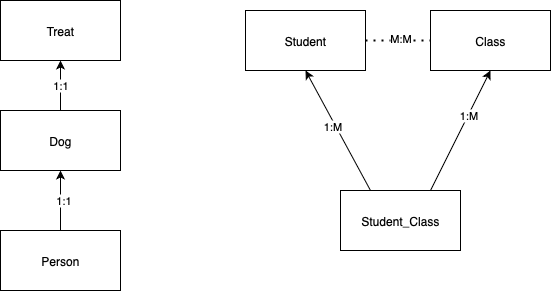
The CIDL be turned into a graph, and using a topological sorting algorithm we would return a valid ordering of dependencies. One problem with this is the kind of topological ordering: do we make it relative to the AST, or relative to SQL.
If the ordering was relative to the AST, in a 1:M relationship like Person( [Dog] ), Dog would come before Person, and it would be Person's responsibility as a model to place a key to itself on Dog.
In the same case, if the ordering was relative to SQL, Person would come before Dog, because Dog holds an FK to person, and Dog cannot be inserted before Person.
It seems obvious the best choice is to do SQL ordering, but the challenge is that the Dog model in our AST has no idea it has a dependency to Person, we would have to somehow forward Person's foreign key properties to Dog. Alternatively, we try to turn AST ordering into SQL ordering in some trivial way. For now, I'll work with SQL ordering.